




Introduction
Regular Expression or RegEx for short is a tiny language that allows you to search matches in strings.
In Python, it is accessible through the re module.
Using it, you can check if the string is in the correct format, if the string contains some characters, extract only part of a long string,...
With a combination of metacharacters and literal characters, you concatenate a pattern used for search inside a string.
re module provides multiple different ways for searching for a pattern in a string.
re.match() Searches for a pattern at the beginning of the string and returns the first occurrence. It returns a match object if a pattern appears at the beginning of the string or
Noneif there is no match at the beginning.re.search() Searches for a pattern through the whole string and returns the first occurrence. It returns a match object if a pattern appears anywhere in the string or
Noneif there is no match.re.findall() Searches for all occurrences of the pattern in the whole string. It returns a list of all matches.
Syntax for RegEx is quite extensive. I don't provide a cheatsheet in this post, you can read through this one for more in-depth knowledge of the syntax
What will you learn?
We will go through some common cases of using RegEx:
- Numbers
- Percents
- Decimals
- Amounts
- Emails
- Correct format
- Extracting part of an email
- Passwords
- Password strength errors
- Password validation
- Date
Examples in this blog are not optimized and do not cover edge cases. Covering edge cases and optimization hurts readability and makes it harder to learn regex.
Prerequisites
- basic knowledge of Python
Numbers
Percents
import re
def get_percents(string):
percent_pattern = r'[0-9]+%'
percents = re.findall(percent_pattern, string)
return percents
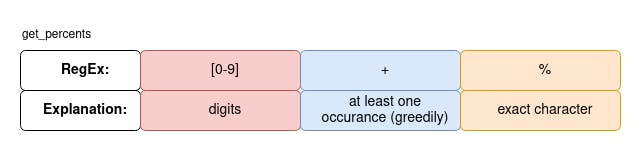
Searching for a percent pattern is one of the easiest. You search for at least one digit (it may be more) followed by a % sign.
"74% of girls express a desire for a career in STEM fields." => ["74%"]
"A whopping 80% of those in the field are male, while only 20% are female." => ["80%", "20%"]
This works only for integers. If you want to catch also decimal numbers, you need to combine it with RegEx for decimals.
Decimals
import re # import regex module
def get_decimals(string):
decimal_pattern = r'[0-9]+[.,][0-9]+'
decimal_numbers = re.findall(decimal_pattern, string)
return decimal_numbers

Decimals look a little more complicated, but the basic idea is the same.
You look for at least one digit, followed by either . or a , followed by at least one digit.
"The number π is approximately equal to 3.14159." => ["3.14159"]
"Niger: 7.03 children born/woman; Angola: 5.49 children born/woman; Madagascar: 4.36 children born/woman;" => ["7.03", "5.49", "4.36"]
Amounts
import re
def get_amount(string):
amount_pattern = r'[0-9]+[.,]*[0-9]*[ ]*[€$]'
amounts = re.findall(amount_pattern, string)
return amounts

Considering many different styles, searching for an amount can be complicated. Here we checked for a basic example. At least one number (can be a decimal or integer) and a € or a $ sign at the end - they may be separated with space.
"In 2018, women in the US receive 250$ less than men when it comes to software development jobs." => ["250$"]
"Computer: 2600€, Mouse: 7.99 €, Screen: 99,9€" => ["2600€", "7.99 €", "99,9€"]
Valid email
import re
def check_email_format(email):
email_pattern = r'\S+@\S+\.\S+'
# \S+ at least one char (greedy)
# @, . - exact match
if re.match(email_pattern, email):
return True
else:
return False

This is a very simple email check. You check if there are any amount of non-whitespace characters that are broken by @ and a .
$%&#$@123.# would also be valid with this check.
"john@doe.com" => True
"%#$@1.2" => True
"python.org" => False
Improved valid email
import re
def check_email_format_improved(email):
email_pattern_improved = r'[a-z0-9.]+@[a-z0-9]+\.[a-z]+'
if re.match(email_pattern_improved, email):
return True
else:
return False

Here you make stronger requirements. You want either lowercase characters or numbers ("gir1cod3") that are followed by @,
followed by lowercase characters or numbers ("@gmai1"), a dot, and at least one lowercase character (".com").
"john@doe.com" => True
"%#$@1.2" => False
"python.org" => False
Get the recipient
import re
def get_recipient_from_mail(email_recipient):
recipient_pattern = r'([a-z0-9.]+)@[a-z0-9]+\.[a-z]+'
recipients = re.findall(recipient_pattern, email_recipient)
return recipients

The pattern for a recipient is very similar to the improved valid email pattern. The only difference is, we added brackets ().
If we include brackets, we're extracting only the part of the match inside the brackets. But we still need the whole match.
"We got an answer from python@python.org that was sent to john@doe.com" => ["python", "john"]
"We got a reply from most of the emails: python@python.org, john@doe.com. But we haven't got an answer from idontreply@whatever.com." => ["python", "john", "idontreply"]
Passwords
Password strength
You know when you get those annoying little messages, what you additionally need to put in your password because the current one is not strong enough? This is how you can do it:
import re
def password_check_parts(password):
uppercase_pattern = r'[A-Z]'
lowercase_pattern = r'[a-z]'
number_pattern = r'[0-9]'
special_pattern = r'[@#$%^&+=!.]'
errors = []
valid = False
if not re.search(uppercase_pattern, password): # used search, because it can be anywhere in the string, match looks only at the beginning
errors.append("Use at least one uppercase char")
if not re.search(lowercase_pattern, password):
errors.append("Use at least one lowercase char")
if not re.search(number_pattern, password):
errors.append("Use at least one number")
if not re.search(special_pattern, password):
errors.append("Use at least one special character")
if not errors:
valid = True
return valid, errors
Here we have bunch of simple patterns, each one checking just for one thing. That way you know exactly what's missing in the provided password, not just that "something's wrong".
[A-Z]=> any uppercase character[a-z]=> any lowercase character[0-9]=> any digit[@#$%^&+=!.]=> any character in the set; if the user uses*as their special character, this is gonna fail;
"something" => (False, ['Use at least one uppercase char', 'Use at least one number', 'Use at least one special character'])
"somethinG1" => (False, ['Use at least one special character'])
"12tesT3#" => (True, [])
Valid password
import re # import regex module
def password_valid(password):
# at least one uppercase char, at least one lower case character, at least one number, at least one special char,
# password_pattern = "[A-Za-z0-9@#$%^&+=]{8,}"
password_pattern = r'(?=.*[A-Z])(?=.*[a-z])(?=.*[0-9])(?=.*[@#$%^&+=!.])'
if re.match(password_pattern, password):
return True
else:
return False
This regex is the hardest to understand in the whole post.

(?= creates a Lookahead.
Lookahead means that although it checks if the pattern in the Lookahead brackets follows the current position of the regex engine.
This part checks only immediately behind the regex engine's position.
If you want it to look further, you have to add 'binoculars'. You do that by adding .*.
That means that between the current position of the regex engine and the part that matches the pattern, can be any amount of any characters (including 0 or just whitespace).
When putting all the searched patterns inside the Lookahead brackets, the regex engine doesn't move.
It just checks if can see all the Lookahead patterns somewhere.

"Something123!" => True
"1tEsT@" => True
"#$%#1" => False
Date
Valid date
import re
def check_date_format(date):
date_pattern = r'[0-9]{4}-[0-9]{2}-[0-9]{2}'
if re.match(date_pattern, date):
return True
else:
return False

We're looking for 4 numbers (year), 2 numbers (month), and 2 numbers (day), divided by -.
The number in curly braces {} tells us exactly how many occurrences we want.
"2020-11-05" => True
"20-01-05" => False
Some text I used for examples, was taken from techjury.net/blog/women-in-technology-stati..
Conclusion
The possibilities of using RegEx are almost limitless, here we covered only a few basic cases. Googling for the patterns usually gives you either very basic examples that help you nothing or complicated patterns you can copy, but can't understand. The patterns we created are not fireproof, rather they are meant to help you understand the idea behind regex.
After going through the examples you should be able to understand RegEx that was written by someone else, create your own, and improve our examples.
Photo by Skies & Scopes on Unsplash