What is list comprehension
List comprehension is a concise way used instead of for-loop when you want to create a new list based on another iterable (list, tuple, dictionary, set, string, generator, ...).
You get to do this:
[do_this(element) for element in thislist if thisistrue]
instead of this:
my_list = []
for element in thislist:
if thisistrue:
my_list.append(do_this(element))
It's easily recognizable and more readable than (at least) 3-lines long for-loop.
It's usually faster and helps you maintain your code clean and simple.
It's especially neater when you want to find the common elements from two lists. You'd need two for loops for that and still only one "not-that-complicated" line for list comprehension.

The result of a list comprehension is always a new list, that's why the expression is in square brackets (there is also a dictionary comprehension, where the result is a dictionary and set comprehension where the result is a dictionary/set accordingly).
There are three parts of the comprehension inside the brackets:
- what to do (e.g. add 2 to each element)
- for what in which list (e.g. for element in the list of numbers)
- when (e.g. when the element is dividable by two)
The third part, if, can be omitted. In that case, the expression will be performed on each element of the old list and the length of the new and old list will be the same.
A very simple showcase of a list comprehension would be this:
[x+2 for x in [2, 3, 4]]
You add 2 to each item in the list ([2+2, 3+2, 4+2]) because there is no condition.
But let's say we want the addition to be performed only on even numbers:
[x+2 for x in [2, 3, 4] if x % 2 == 0]
Now the addition is performed only on 2 and 4 ([2+2, 4+2]). 3 is not an even number, so it is omitted from the creation of a new list.
Those are two very simple cases, just enough for you to get an idea.
In the real world, you probably won't need to add a number to a list of numbers.
List comprehension in the real world is often used to perform some kind of filtering.
Filtering
When you want to create a new list with just some of the elements from the old list, you set a condition with if that will let only some of the elements pass.
You can either do something with the elements that match the condition (new_x = x+2) or not (new_x = x).
Simple filtering
You know those "The hottest day this summer" news titles?
Let's say you have the list of the daily temperatures from the summer and you want to get only the temperature higher than 30°C.
This is how you do it:
all_temperatures = [28, 23, 38, 32, 28, 31, 29, 33]
highest_temperatures = [temperature for temperature in all_temperatures if temperature > 30]
In this case, you didn't change the elements. You just took the numbers higher than 30 from the all_temperatures list and put them into the highest_temperatures list.
The all_temperatures list is unchanged.
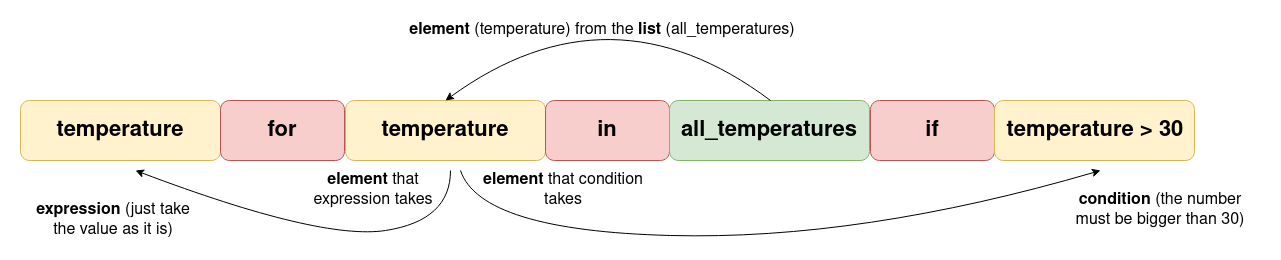
Filtering based on the length of the element
You got a list of messages from your users. The field was required, so some of them just wrote few random letters to skip it.
You want to filter out the ones with some values - the string has to be at least 10 characters long:
messages = ['Praesent orci nulla, pellentesque a consectetur id.', '/', 'zblj', 'Aliquam pellentesque diam et nibh hendrerit semper. ', 'test']
valuable_messages = [message for message in messages if len(message) > 10]
As in the previous case, you didn't do anything with the element on the list. You just checked if it's long enough and if it is, you added it to the new list.
Filtering based on part of the tuple
Let's say you have a tuple of tuples with a name and a grade a student got for the test. Some of the students were sick, so they weren't graded and now you want to know which of the students you need to prepare another test.
grades = (('Anna', 'B'), ('May', 'A'), ('Tina', ''), ('Claire', ''), ('Beth', 'A'))
ungraded = [name for name, grade in grades if not grade]
As you can see, this is not a list, but a tuple of tuples. In the list comprehension, you declared that the first part of the inside tuple is called name and the second one is called grade (this is called tuple unpacking).
Those names are of your choosing and matter only for readability purposes. For Python's sake, they could be called zblj and gn.
You take the name from each tuple in the outer tuple and put it in the new list (there won't be grades listed in the new list, just names). But the element (name) goes to the new list only if the second part of the tuple (grade) is an empty string.
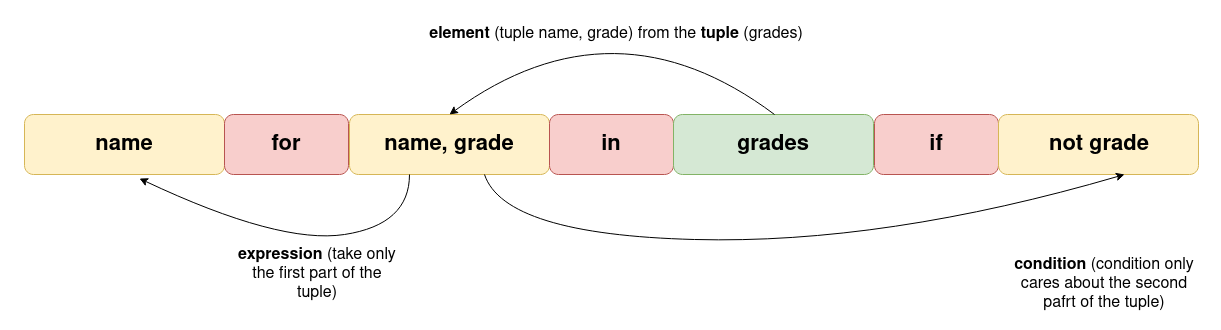
This is the only case we didn't create a list out of the list but out of a tuple. It doesn't matter what the source object is, only that is iterable. The outcome, however, is always a list.
Filtering and changing the element
If you need to extract numbers from the list of strings, you can check if the string contains only digits and if it does, you can convert it to an integer.
alphanumeric = ["47", "abcd", "21st", "n0w4y", "test", "55123"]
numbers = [int(string) for string in alphanumeric if string.isdigit()]
On the new list are the elements from the old list that contained only digits and were transformed to integers.
Working with more than one list
Another possibility where list comprehension can be useful is when you need to somehow combine two or more lists.
Combining all the elements
You want to order mobile phones for your store. Your boss told you which color and which models to order.
To make it easy for yourself, you can combine all the selected colors with all the selected models:
colors = ["red", "blue", "black"]
models = ["12", "12 mini", "12 Pro"]
order = [(model, color) for model in models for color in colors]
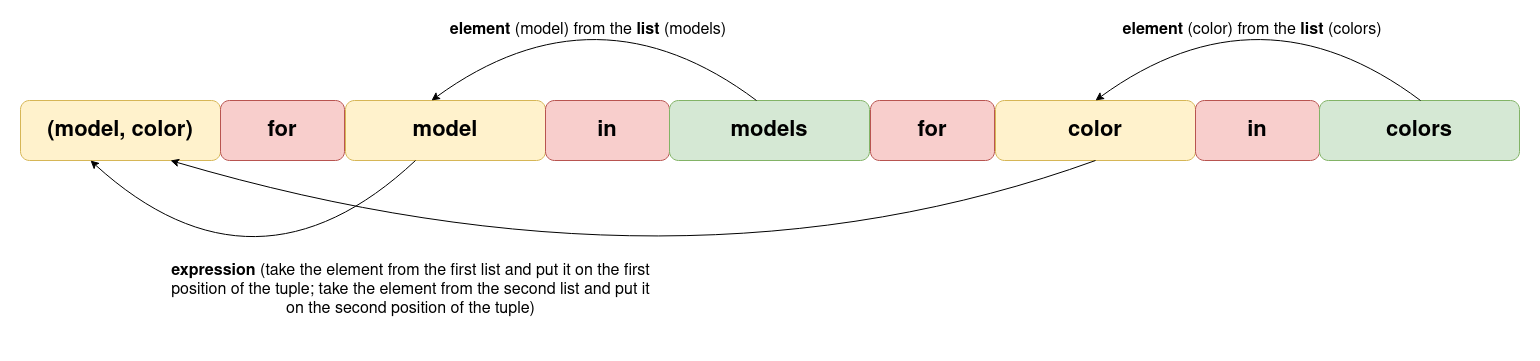
Here you combined every item from the first list with every item on the second list. The length of the new list will be the product of both lengths (len(list_1) * len(list_2))
Common elements
Here's one for the Disney fans. You have a list of all the characters from Frozen. And you have a list of all the Disney princesses.
Now you would like to know which Disney princesses are in the Frozen movie.
frozen = ["Anna", "Elsa", "Sven", "Olaf"]
princesses = ["Rapunzel", "Elsa", "Anna", "Ariel"]
princesses_from_frozen = [frozen_char for frozen_char in frozen for princess in princesses if frozen_char == princess]
In this case, you go through all the elements in the first list and you compare every single element with all the elements from the second list.
The new list contains only the elements that appeared on both lists.
This might be the easiest to explain if you see how this would look with a for-loop:
princesses_from_frozen = []
for frozen_char in frozen:
for princess in princesses:
if frozen_char == princess:
princesses_from_frozen.append(frozen_char)
If you didn't previously, now you probably get the beauty of list comprehension?
Combining elements with the same position
names = ["John", "Mary", "Lea"]
surnames = ["Smith", "Wonder", "Singer"]
ages = ["22", "19", "25"]
combined = [F"{name} {surname} - {age}" for name, surname, age in zip(names, surnames, ages)]
Here we need to use the Python zip function.
zip function returns a zip object, which is an iterator of tuples where the elements on the same position from different lists are paired together.
So, zip(names, surnames) would need to be turned to something readable with
tuple():
print(tuple(zip(names, surnames)))
and would return:
(('John', 'Smith'), ('Mary', 'Wonder'), ('Lea', 'Singer')).
After we created a zip object, we assigned names for each element in the tuple - name, surname, age and combined all three in a string for each tuple (F"{name} {surname} - {age}").
If the lists are of different lengths, the zip will work with the shortest list. So the length of the new list will be the same as the length of the shortest list.
Using it with function
If you need to do quite a lot with the elements, you can use a function in the expression and do the logic in the function. That way, your list comprehension stays short and readable.
Convert euros to dollars
def convert_to_dol(eur):
return round(eur * 1.19, 2)
prices = [22.30, 12.00, 0.99, 1.10]
dollar_prices = [convert_to_dol(price) for price in prices]
The above example would also work written like this:
dollar_prices = [round(price * 1.19, 2) for price in prices]
but it's not as readable, right?
Conclusion
List comprehension can be confusing at first, but it's really worth learning.
You might have to do few more cases, but after a while, it will be easier to make sense of a list comprehension than of a for loop, I promise.
However, don't go switching all of your for-loops with a list comprehension.
It is only to be used when you need to create a new list from some other list(s).
If you're looking for some practice, here are a few ideas:
- Add a list of possible memory sizes to Combining all the elements example and create tuples combined from all three lists.
- Take the code from Common elements example, add a new list -
princesses_i_like, and try to find the name that appears on all three lists
(you can put in any names you want but if you want to get a result, you have to include Anna or Elsa).
- Take the code from Combining elements with the same position example and combine the data only for people older than 20.
You can find the solutions in the comments.
If you think of another good use case for list comprehension, feel free to post it in the comments.
Image by Alexandra_Koch from Pixabay










